你的位置:手机真钱老虎机电玩城最新版下载 > 新闻资讯 > 真钱上分老虎机游戏app平台这是 MiniMax 第一次发布开源模子-手机真钱老虎机电玩城最新版下载
真钱上分老虎机游戏app平台这是 MiniMax 第一次发布开源模子-手机真钱老虎机电玩城最新版下载
发布日期:2025-02-13 11:21 点击次数:145
作家 | Li Yuan
裁剪 | 郑玄
大模子时间还是精采迈入第三年。
归来昔时的两年,不禁令东说念主感触。每年齐有基座大模子架构还是尘埃落定的声息,然而每年,时期齐在飞速地迭代改进,突破东说念主们设想。
2024 年,OpenAI 的推理模子,通过对模子架构的改进,用 RL 的枢纽延续 Scaling Law,让大模子的技艺水平赓续进展;而中国公司也并莫得过时,价钱屠户 DeepSeek 通过 MLA 的架构改进,让推理资本平直缩短了一个数目级。
2025 年开年,令东说念主欢欣的是,咱们看到了一向在东说念主们印象中是「低调作念居品」的 MiniMax 公司,也加入了开源行列,将早先进的底层时期平直与社区和行业共享。
1 月 15 日,大模子公司 MiniMax 精采发布了 MiniMax-01 系列模子。它包括基础谈话大模子 MiniMax-Text-01,和在其上集成了一个轻量级 ViT 模子而建造的视觉多模态大模子 MiniMax-VL-01。
开源界面|图片开头:GitHub
「卷」起来的大模子公司,令东说念主乐见。开源会进步改进着力,越来越好的基座模子之上,才搭建越来越有用的诳骗,进入千门万户,帮东说念主们目田出产力。
这是 MiniMax 第一次发布开源模子,一脱手即是一个炸裂模子架构改进:新模子遴荐了 MiniMax 特有的 Lightning Attention 机制,模仿了 Linear Attention(线性防卫力)机制,是全球第一次将 Linear Attention 机制引入到贸易化范围的模子当中。
后果亦然立竿见影,模子凹凸文长度平直达到了顶尖模子的 20-32 倍水平,推理时的凹凸文窗口能达到 400 万 token。模子后果坐窝在国际上引起了关心。
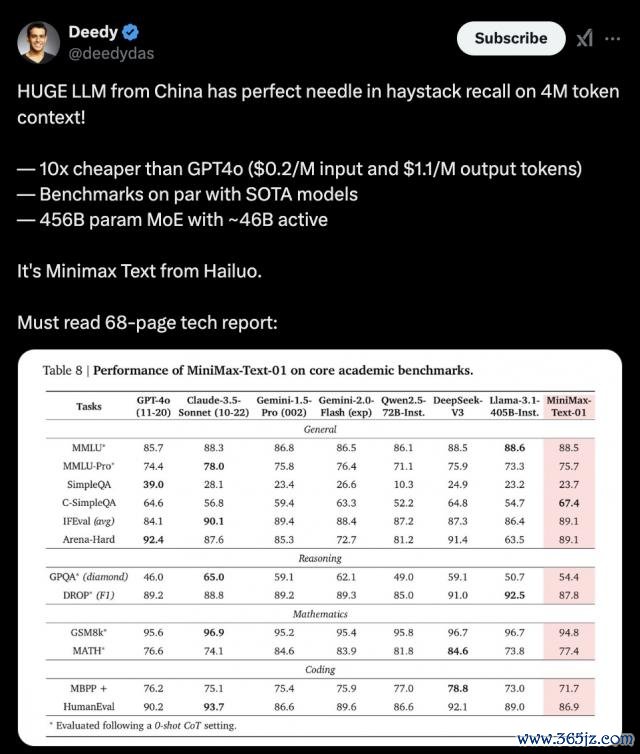
X 用户惊叹 MiniMax-Text-01 不错在 400 万 token 上完结完好意思的炊沙作饭 | 图片开头:X
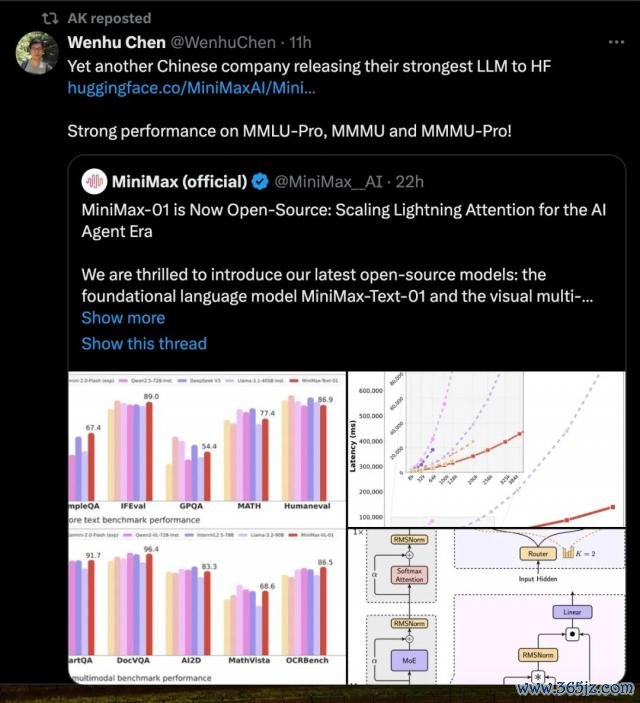
另一个来自中国公司的繁密模子,在学术测试集上施展优胜|图片开头:X
模子的凹凸文窗口,指的是模子在生成每个新 token 时,本体参考的前边内容的范围。就像是模子能够一次性从书架上取下的竹帛数目。模子的凹凸文窗口越大,模子生成时不错参考的信息量就越多,施展也就愈加智能。
站在 2025 年齿首的时辰点,长凹凸文窗口还有一个新的敬爱:为模子的 Agent 才气,打下坚实基础。
业界公认,2025 年,Agent 才气将是 AI 届「卷生卷死」的要点,连 OpenAI 齐在本周内推出了 Tasks,一个 AI Agent 的雏型。在 2025 年,咱们很有可能看到越来越多果然「全自动的」AI,在咱们的活命中起作用。以致不同「全自动的」的 AI 共同互助,帮咱们处理事务。而这对基座模子的才气,有极大的锤真金不怕火。而长凹凸文是 Agent 才气完结的必要条目。
看起来,2025 年,基座大模子之战仍未收尾;中国公司发力,也才刚刚开动。
01
Linear Attention 架构
的第一次大范围使用
这次 MiniMax 开源的模子,最大的改进点,在于使用了 MiniMax 特有的 Lightning Attention 机制,这是一种线性防卫力。
在传统的 Transformer 架构中,最「烧」算力和显存的部分时时是自防卫力(Self-Attention)机制。 原因在于,要领的自防卫力需要对悉数的词(Token)两两蓄意防卫力分数,蓄意量跟着序列长度 n 的增长是精深级(O ( n ² ) )。
如若用平凡的谈话来描写,肖似于你在举办一场联谊会,东说念主好多。如若每个东说念主齐要两两打呼叫,雷同资本会跟着东说念主数增多而急剧飞腾,每个东说念主齐得重迭无数次「合手手」。
这带来了一系列的问题——其中一个即是,联谊会的东说念主数,也即是模子的凹凸文的窗口,很难无尽扩张。硬要扩张,对于算力的需求就迥殊高。
为了应答这一挑战,传统上,参谋东说念主员冷落了各式枢纽来缩短防卫力机制的蓄意复杂度,包括荒芜防卫力、Linear Attention(线性防卫力)、长卷积、情景空间模子和线性 RNN 等边幅。
这次 MiniMax 开源的模子,即是借用了其中的 Linear Attention(线性防卫力)的边幅。
Linear Attention 的念念路就像给会场安排了几位「速配助理」。每个东说念主先把我方的重要信谢绝给助理,比如「但愿顽强什么样的东说念主、擅长什么」。助理整理这些信息后,平直告诉每个东说念主最相宜交谈的对象。这样,各人无谓一个个自我先容,整个匹配进程更高效,雷同资本大幅缩短。
不外,Linear Attention 之前天然在表面上有所改进,但在贸易范围模子中的遴荐有限。而 MiniMax 团队则第一次考据了 Linear Attention 机制在贸易范围的大模子之上的可行性。
这意味着一项时期从实验室走向果然寰宇。
MiniMax 团队使用了一个传统的 Linear Attention 的变种,被 MiniMax 团队称为 Lightning Attention。Lightning Attention 措置了现存 Linear Attention 机制蓄意着力中的主要瓶颈:因果积存乞降操作的松懈,使用新颖的分块时期,有用回避了累加和操作。
在一些特定任务,如检索和长距离依赖建模上,Lightning Attention 的性能施展可能不如 Softmax 防卫力强。
MiniMax 团队又引入了夹杂防卫力机制措置这一问题:在最终的模子架构中,在 Transformer 的每 8 层中,有 7 层使用 Lightning Attention,高效处理局部相干;而剩下 1 层保遗留统的 Softmax 防卫力,确保能够捕捉重要的全局凹凸文。
这样的架构改进,后果十分惊艳。
MiniMax-01 系列模子参数目高达 4560 亿,其中单次激活 459 亿。在主流模子现在的凹凸文窗口长度仍然在 128k 傍边的时候,MiniMax-01 系列模子能够在 100 万 token 的凹凸文窗口上进行磨砺,推理的时候凹凸文窗口可除外推到 400 万 tokens,是 GPT-4o 的 32 倍,Claude-3.5-Sonnet 的 20 倍。
在面向践诺情景,进行长凹凸文多任务进行深切的会通和推理的第三方测评 LongBench v2 的最新限度中,MiniMax-Text-01 仅次于 OpenAI 的 o1-preview 和东说念主类,位列第三。
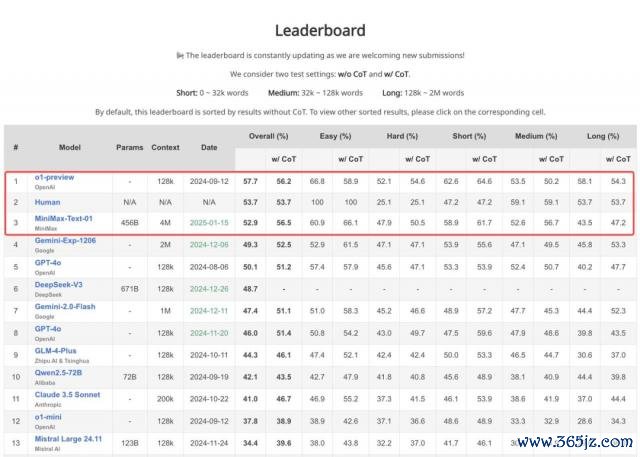
模子在 LongBench v2 上的评测施展 | 图片开头:GitHub LongBench
在模子的基础施展上,MiniMax-01 系列模子也在要领学术基准测试中可与顶级闭源模子相比好意思。不仅如斯,在模子凹凸文长度迟缓变长的进程中,模子的施展着落也最平缓——部分模子天然晓示凹凸文窗口长度较长,但果然使用起来,在长凹凸文情况下,后果并不好。
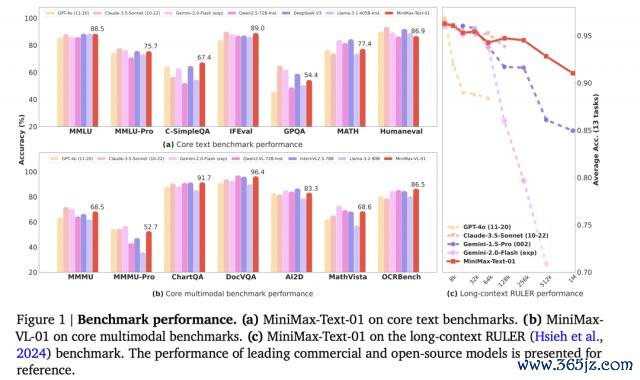
MiniMax-01 系列模子可与顶级闭源模子相比好意思 | 图片开头:MiniMax 论文
MiniMax 团队对比了在 CSR(学问推理)、NIAH(大海捞针)和 SCROLLS 等基准测试上,在同样的蓄意资源下,用遴荐了 7/8Lightning Attention 和 1/8 的 Softmax 的夹杂防卫力模子不错放更多参数、处理更普遍据,况兼磨砺后果还比只用 Softmax 防卫力的模子更好,亏损更低。
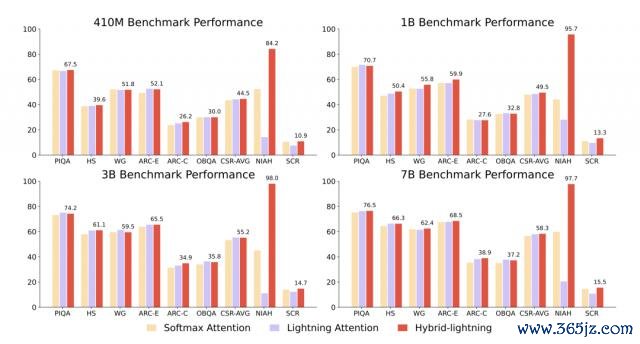
基准测试上夹杂 Lightning Attention 的架构施展更好 | 图片开头:MiniMax 论文
02
为 Agent 时间爆发的前夕作念准备
自 2024 年开动,长凹凸文一直是模子迭代的一个弥留标的。
在这个范围,国外的 Google、Anthropic,国内的 Kimi,齐是顽强的参加者。2024 年年末,DeepMind 的 CEO Demis Hassabis 曾暗示,在里面测试中,Google Gemini 正在向无尽凹凸文窗口发起冲击。
简略有东说念主会困惑,这次 MiniMax 发布的 MiniMax-01 系列模子,凹凸文窗口长度还是达到 400 万 token,如若按照 1 个 token 约等于 1.7 个汉文汉字的蓄意边幅,还是约等于 700 万字的凹凸文窗口。东说念主类需要和 AI 聊出这样多的凹凸文吗?
谜底是, 盯住长凹凸文的各家公司,可能盯住的并不是现在的一问一答的问答 AI 场景,而是背后的 Agent 时间。
不管是单 Agent 所需的赓续挂念,如故多 Agent 互助所带来的通讯,长链路的任务齐需要越来越长的凹凸文。
长凹凸文,在多种 Agent 诳骗场景中,将具有极大的敬爱。
在搜索场景中,这可能意味着用户不错一次性看到更多谜底的详尽,平直取得更精确的回答。
异日的着力器具中,这可能意味着用户领有了无尽的使命挂念。在无数版块的修改之后,当甲方让你如故用第 1 版的著述结构和第三版的小标题的时候,你不错无痛文告「好的」,然后让 AI 一键生成两个版块的交融。
异日的学习器具中,这可能意味着用户不错平直具有更大的知识库。平直上传一册讲义,就能让 AI 说明其中的内容,进行教悔。
而在和 AI 助理的对话中,它将像奢睿的东说念主类助理一样,果然记着你之前说过的话,并在你需要的时候「难忘来」。MiniMax 团队的论文当中的一个场景就很能评释问题。
模子被要求从最多 1889 条历史交互(英文基准)或 2053 条历史交互(汉文基准)中精确检索出用户的一条历史互动——用户重迭要求 AI 写对于企鹅的诗歌,同期进行了多轮不筹商的对话,而在终末,要求 AI 提供第一次写的对于企鹅的诗。而 MiniMax-01 仍然很好地完成了这一任务。

长凹凸文的任务施展 | 图片开头:MiniMax 论文
对于 Agent 来说,另一个弥留才气,则是视觉会通 —— MiniMax 这次同系列也发布了 MiniMax-VL-01。这是一个同样遴荐了线性防卫力架构、以及领有 400w token 凹凸文窗口的视觉多模态大模子。
在 2024 年 Rayban-Meta 眼镜爆火之后,本年的智能硬件的一大看点在于 AI 眼镜能否果然让 AI 成为东说念主们的随身助手。而能成为随身 AI,AI 必须的才气即是长凹凸文——记着你的悉数活命场景,才能在随后为你提供个性化的领导和建议。
这样的挂念将是「真挂念」,与 ChatGPT 现在的挂念功能所能提供的浅显后果十足不同。
要果然完结随身的 AI Agent,跨模态会通、无尽凹凸文窗口齐是基础才气。
论文终末, MiniMax 暗示异日将在线性防卫力这通盘径上作念到极致,尝试十足取消 Softmax 防卫力层,最终完结无尽的长凹凸文窗口。
03
基座模子改进未死,
中国公司远景繁花
值得防卫的是,这次是 MiniMax 公司,第一次推出开源模子。
这次的大模子定名的 MiniMax-01 系列,在 MiniMax 的里面序列中,底本是 abab-8 系列模子。
MiniMax 在上一代 abab-7 模子中,还是完结了线性防卫力和 MOE 的架构,而在 abab-8 中,取得了更好的后果。
这次,MiniMax 取舍在这个时辰点,将模子开源出来,并以这个节点为开动,从头定名模子 MiniMax-01。
这似乎代表着 MiniMax 的公司玄学的一种改换。
在过往,MiniMax 公司给外界一向的印象是:业务很赋闲,作念事很低调。
从星野、Talkie 到海螺 AI,MiniMax 有我方赤诚的一波用户群体。在客岁的公建造布中,MiniMax 也曾暗示每天还是有 3 万亿文本 token 的调用,在国内 AI 公司中名列三甲。
这些诳骗背后的 AI 时期则一直较为机密,在此之前主要用于扶持公司本人的业务。 这次开源,似乎是一个滚动,是 MiniMax 第一次对外高调展示时期实力。
MiniMax 方面暗示,模子不错在 8 个 GPU 单卡、640GB 内存上,就能够完结对 100 万 token 进行单节点推理。但愿这次开源匡助其他东说念主建造能够突破现时模子的局限。
记忆过往,自 OpenAI 推出 ChatGPT、Meta 发布 Llama 系列开源模子以来,一直有声息暗示基座模子的改进已趋于拆伙,或仅有少数国际科技巨头具备异日模子架构改进的才气。
最近两次中国公司的开源当作,告诉咱们并非如斯。
2024 年,DeepSeek 凭借其突破性的 MLA 架构,颤动了全球 AI 行业,解说了中国企业的时期创造力。
2025 年齿首,MiniMax 再次以其全新的 Lightning Attention 架构刷新了行业领路,考据了一条此前非共鸣的时期旅途。
中国 AI 公司不仅具备工程化和贸易化的才气,更有才气鼓动底层时期改进。
新的一年,非论是 AI 诳骗的普及,如故时期金字塔尖的攻坚,咱们不错对中国 AI 公司有更多的期待。
* 头图来 源:视觉中国
本文为极客公园原创著述真钱上分老虎机游戏app平台,转载请筹商极客君微信 geekparkGO
相关资讯